Keep up with tech in 5 minutes
Get the free daily email with summaries of the most interesting stories in startups 🚀, tech 📱, and programming 💻!
Join 8,000,000+ readers from companies like Anthropic, OpenAI, and more for one daily email
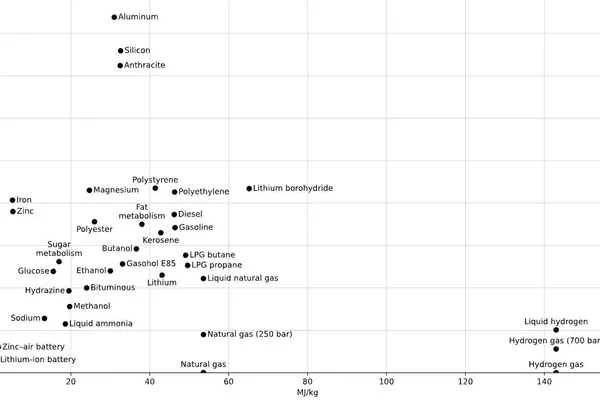
Why Is Everyone Trying to Build a Solid-State Battery? (13 minute read)
Solid-state batteries have several potential advantages over lithium-ion batteries. A solid-state battery would be lighter and safer than the liquid electrolyte used now. This article looks at why solid-state batteries have these advantages compared to conventional lithium-ion batteries. It also looks at how they fit into the broader arc of lithium battery improvements.

Jun 12 | Blog
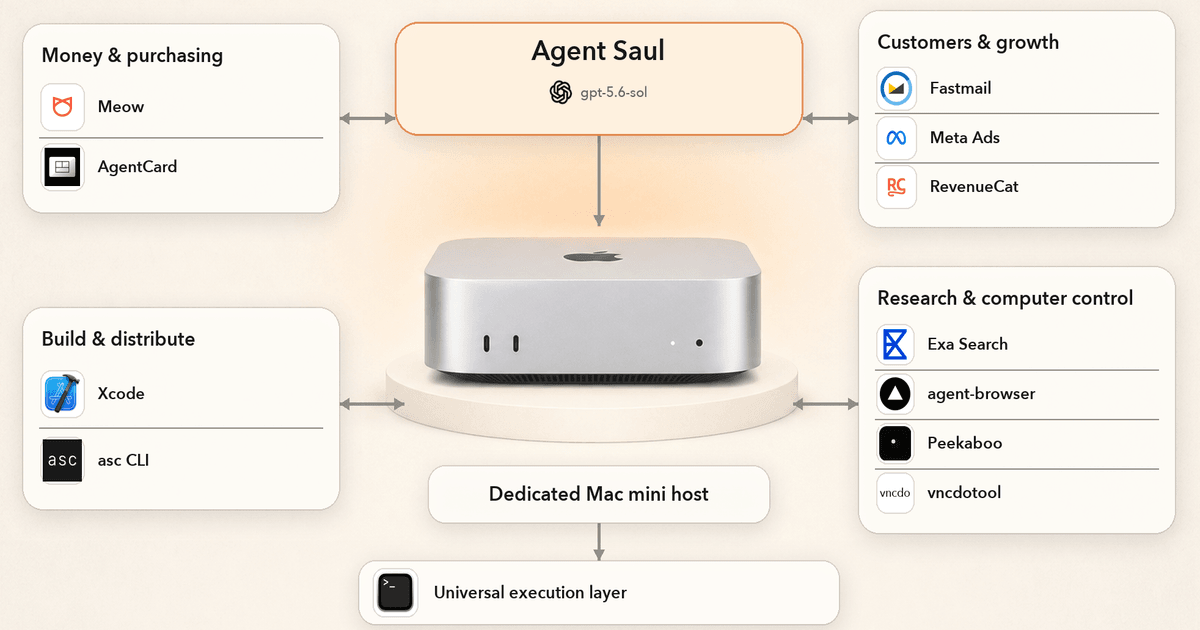
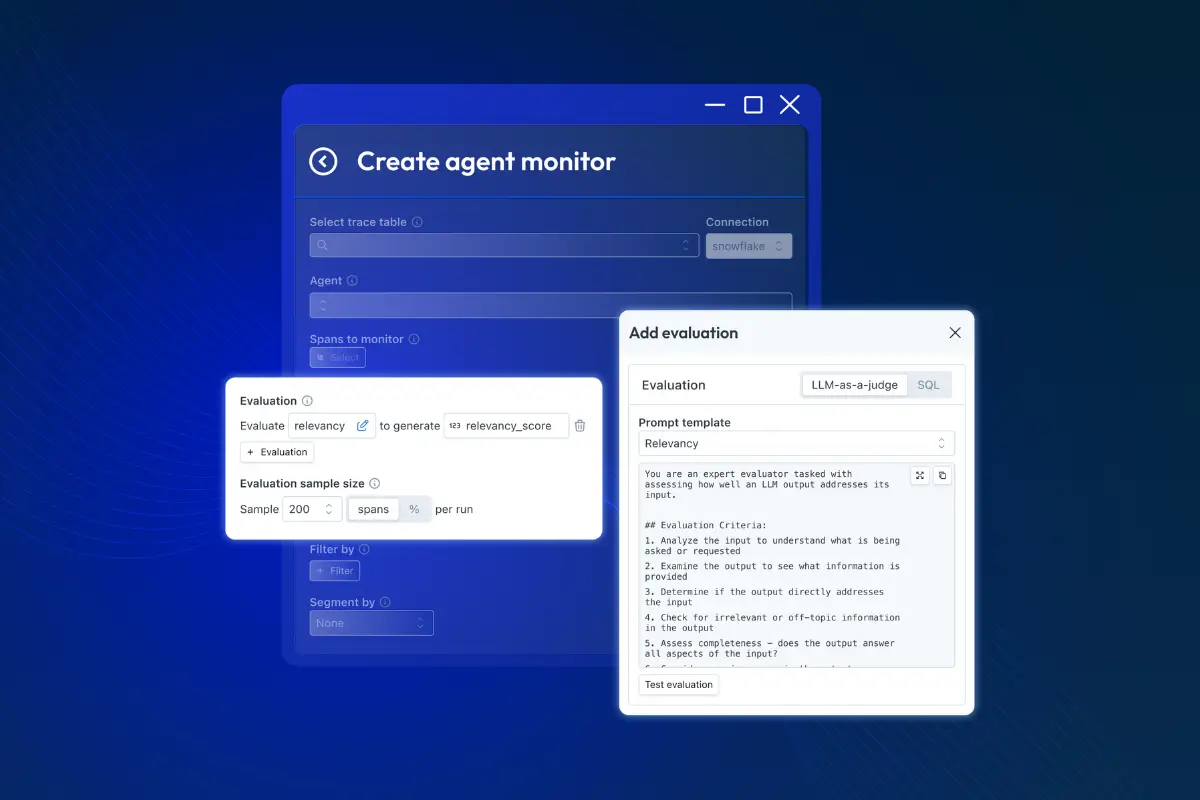
I Tried to Build a Context Layer for My Agent in a Weekend. Reader, I Did Not Build a Context Layer for My Agent in a Weekend.
A "simple" weekend project turns into real infrastructure, and why agent context deserves a boring, reliable foundation.
Sponsored
Jul 31 | AI
Inkling-Small (4 minute read)
Thinking Machines has released Inkling-Small, a 276B-parameter mixture-of-experts model with 12B active parameters. The model retains Inkling's multimodal reasoning, variable thinking effort, and 1M-token context window while using substantially less compute.

Jul 31 | Design
iPhone 20: Rumor has it Apple is Prepping a Radical Redesign (2 minute read)
Reports suggest Apple's 20th-anniversary iPhone, expected to launch in September 2027, will bring a radical redesign with curved, edge-to-edge glass. Two Pro models are rumored, sized around 6.3 and 6.9 inches, potentially dropping the notch or Dynamic Island entirely. A leaker also claims solid-state buttons with haptic feedback could replace mechanical controls for power, volume, and camera.

Jul 31 | Dev
Stacked pull requests are now in public preview (5 minute read)
Stacked pull requests are now available in public preview on GitHub, allowing teams to break large changes into smaller, reviewable pull requests that can be independently reviewed and merged together. This feature improves the review process by enabling parallel reviews of focused changes, maintaining code quality through existing protections, and allowing for one-click merges of multiple pull requests.